To start of we show a diagram of the current situation:
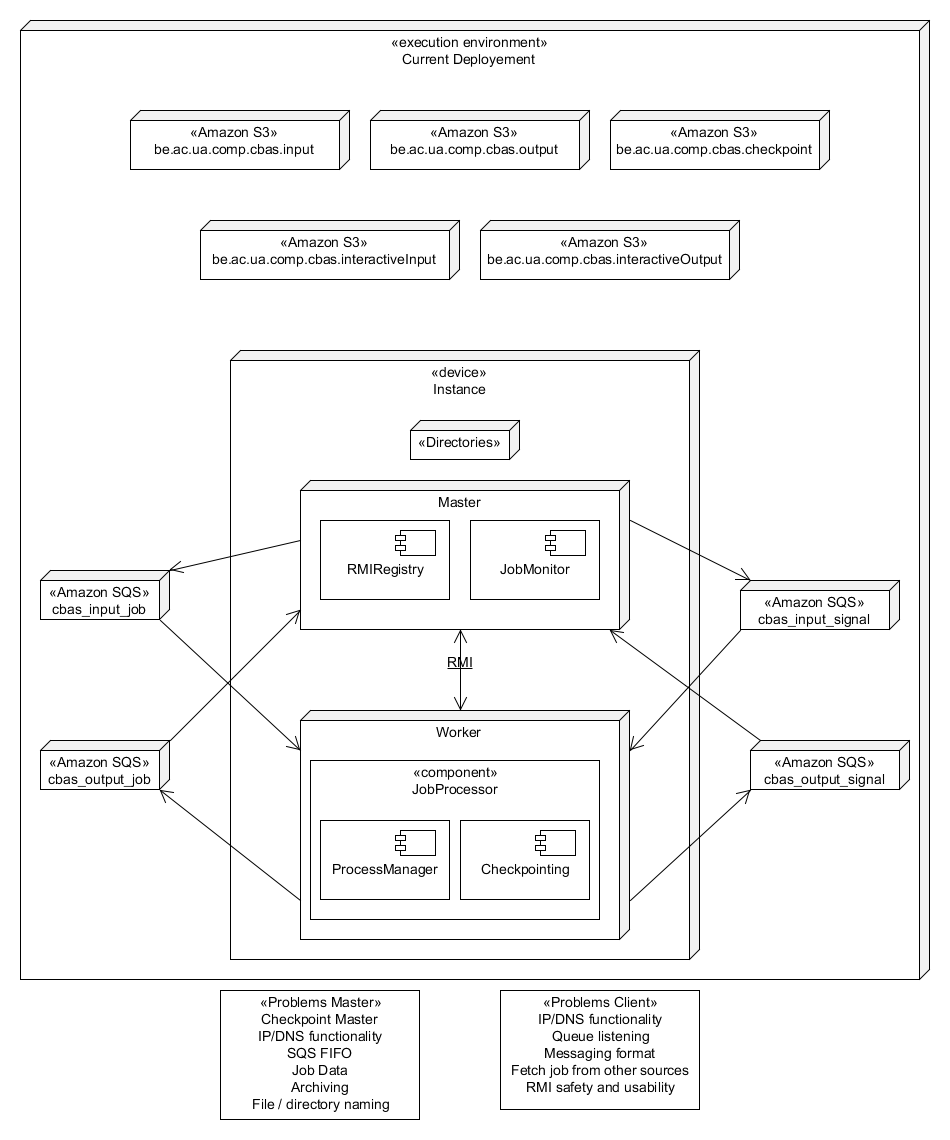
communication goes through RMI and SQS while using S3 for file transfer.
Since it is still a prototype it functioned mainly through the usage of local directories to store jobs and output.
The biggest issues that were noted through the prototype have also been listed, some are fixed in our own proposal but most of them require simple rewriting.
This will be further explained using the diagram of the proposed deployment:

In the prototype the usage of Amazon was limited to SQS and S3.
This has been changed to EC2, SQS,S3, SNS and DynamoDB.
A combination of these services will make us capable of having a robust and safe implementation and solves some of the issues that were present in the prototype.
Next to that it was suggested to provide a web frontend to the system for easy usage. This suggestion was included as well for completeness.
To reduce costs as much as possible we will try to use Amazon's Spotmarket to run both Master and Workers. For this to succeed we require a terminate resilient implementation of these applications.
The ways we provide this are explained further on.
One of the bigger differences with the current prototype is the handling of information concerning jobs. Currently this is simply being stored in a job manager on the master. But whenever a master crashes or is being terminated we have lost all the data concerning these jobs.
Therefor it is suggested to store the information in key-value pares on a dynamodb database on amazon.
This solution entails robustness and scalability. But requires the usage of an additional service which will provide additional costs. But since the size of this database is rather limited, this extra cost will be rather low in comparison to the usage of the different instances.
This approach also provides the advantage of both Master and Worker being able to access this database and making the necessary changes. The problem of not having unique job ids is also solved through the usage of dynamodb since it has the capability of providing these ids.
In this schematic I also represented a possible scenario of distributing multiple masters and their respective workers across the different zones of a region. This mainly to improve robustness and simply as an example.
It would be up to the Master to decide whether it is beneficial to create a new Master on a different zone, simply deploy the workers across zones or even start a Master and workers in a different region.
Another change can be found in the usage of Amazon's Simple Notification Service, this should provide for solutions to several problems. For example the application would no longer require the usage of RMI since this can now be done through SNS messages.
We could now easily detect terminated instances, signals don't need to be send through SQS (which was a problem since SQS does not guarantee FIFO ordering of its messages), ...
The only disadvantage at the moment is the requirement of having an HTTP endpoint to receive these messages. This can be solved through the usage of libraries of which Jetty is an example.
Yet again this is an extra service which will introduce new costs.
It will need to be decided whether it is worth these costs or not.
The already present systems of SQS and S3 were reduced.
For example the signals queue's are no longer needed because of the usage of SNS.
The usage of the interactive buckets isn't needed anymore either, we suggest using a folder
structure within the input and output buckets to reflect for example the different jobs.
These were some of the general changes but the Master and Worker require a more detailed view.
Therefor the following schematic was created:

As can be seen, the Master will be subdivided into 4 different parts.
- HTTP Server : this will be the HTTP endpoint required for using the SNS service. It will have to forward the received messages to other parts of the Master.
- Spot Simulator : the core part of the decision making process. The spotsimulator will be used to decide which bid will be used to request new instances. This simulator has been provided to us in the form of the Broker Prototype from Kurt Vermeersch. In this application only historical data is being used, read from CSV files. There will need to be a system that either provides up to date CSV's or it will have to be expanded to retrieve the current data from the Amazon webservices. The simulator also tries to account for price differences in the different regions, this is something that could be provided if we have at least one Master in each region or if it would be profitable enough to start up a Master in the specific region with some workers. Another issue that will have to be solved is the input format of the simulator and CBAS, a consensus will have to be found between the JDL files used in CBAS and the input files of the simulator. To make things easier I would suggest a new message format namely JSON, since it is easily used in Amazon's services.
- Resource Manager : using the bids of the spotsimulator, this manager will make sure the required amount of spotinstances are present which can then be used by the workermanager. If the price differences between regions are large enough to transfer work from one region to another, this manager could also terminate instances, this decision making process would then need to be added to the simulator because it is not yet present. If the simulator has shown that it is best to start the job in a different region, the job will be posted to this region if a Master already exists, if not we check if it is worth setting up a Master. When this is not the case we will have to make sure to get a bid for this region.
- Worker Manager : Makes the decisions concerning the workers, contains all the communication, prepares the necessary AMI's for jobs to run on. Next to that it will also be responsible for restarting terminated workers. We would restrict the communication between Worker and Master as much as possible to make sure they can still function without having the other around. This is possible because we save all the job data in the DynamoDB database.
The Worker consists out of 3 parts:
- HTTPServer: serves the same purpose as the one within the Master.
- Checkpointing: this should be functionality in control of the checkpointing, ideally this would be done through DMTCP and an additional script which would perform a snapshot of the current state, give it a specific name and saves all information in the job on DynamoDB. The checkpointing functionality within the prototype would prove to be of no use anymore and could be removed.
- JobManager: a manager in control of the job that needs to be executed, this would largely be the same logic that is currently present within the CBAS prototype. Only some optimizations would be put in place as for example the polling for work from SQS would be replaced by SNS posting a message that there is work and the visibility timeout which can be renewed while the job is running.
If multiple workers are working on the same job, some communication is also required between these workers.
The best approach to this system is yet to be determined.
For now the most important part is to find out how the spotsimulator could be integrated and to see if this would require a great deal of change to the original code. Then the efficiency of this simulator will have to be checked and perhaps adjusted for our needs.
In the meanwhile testing will continue on the DMTCP checkpointing mechanism.
Geen opmerkingen:
Een reactie posten