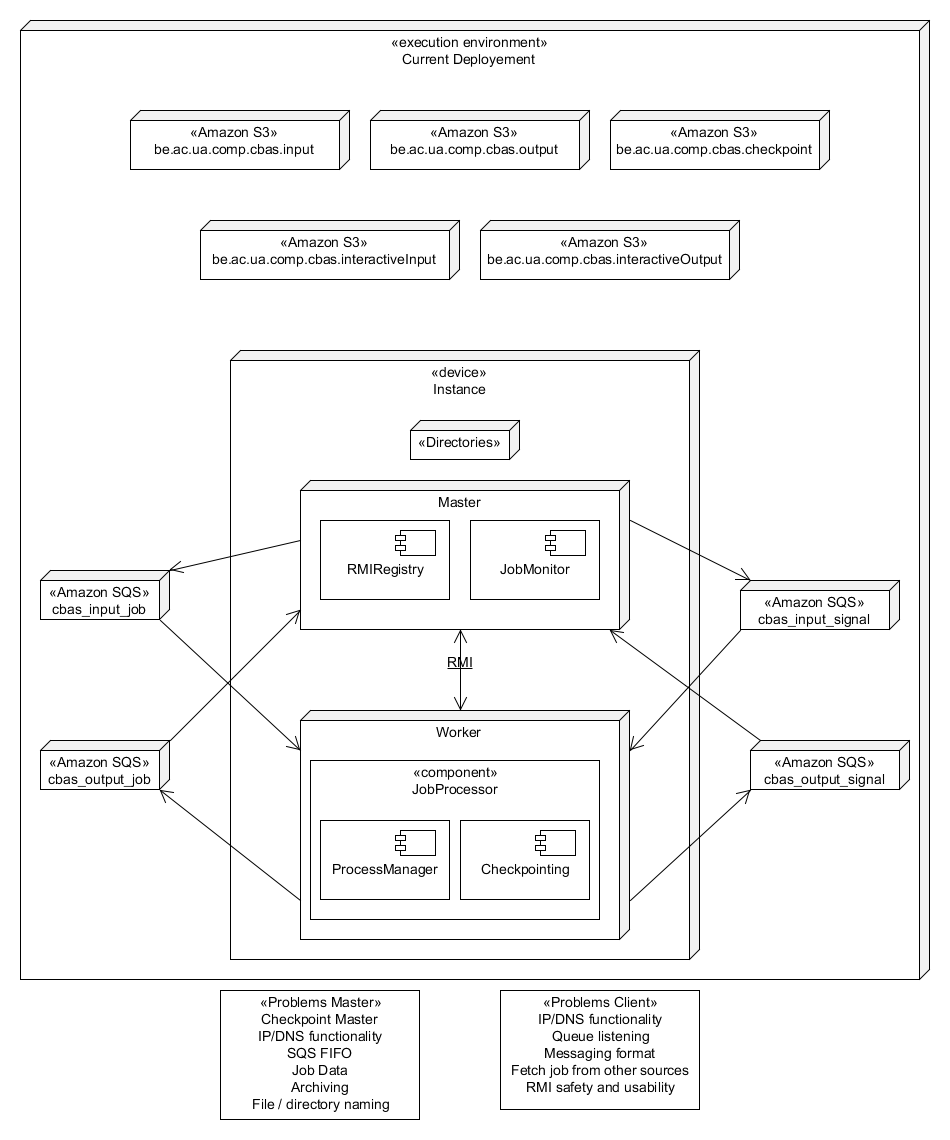
This has proven to be quite the challenge.
Large parts of the code need to be completely rewritten as I also address some of the issues that were stated in the code.
The integration of DynamoDB is going quite well thanks to the Object Persistence technology that is available.
It provides some annotations that can be used together with a Java class and it's methods to map it's data to a DynamoDB table. One of those annotations is DynamoDBAutoGeneratedKey which generates a UUID to be used as the hashkey, this is used to provide unique id's for every job.
Apart from a job table a misc table was also provided, this table has a string as it's key and can contain a string value.
Momentarily this is used to store the bucket names that are used, this is required because those names need to be unique.
Methods are also supplied to create or retrieve the necessary tables, queues and buckets.
The Job Messages classes are altered, some information could be removed since it's now stored in the database and can be retrieved there by both the worker and the master.
Next to that their toString functionality now provides the type of the message as well.
A Job Record now only contains a JobItem which is the annotated Java class representing an item from the job table.
JobRequest was extended to include the outputSandboxFile, in here users can supply a name for their output. Momentarily only one name is supported.
The master is heavily adapted to work with all the changes made until now.
The next point was to test and check the SNS functionality of Amazon.
This requires an HTTP endpoint, for which Jetty was chosen. Some initial testing showed great promise for it's functionality.
The initial plan was to provide SNS topics for every master to make it easy to send messages to the master even from external applications (a possible frontend) and a topic for every job to provide easy communication between master and Worker.
Several problems have been encountered with this approach though:
- Amazon has a maximum of 25 topics for every user.
- Amazon SNS is a fire and forget kind of service
Amazon SNS provides a retry mechanism in which it tries to send the message to all endpoints and retries if it fails. The number of retries is a setting that can be altered, as is the time between every retry.
If we'd use this mechanism to determine if a worker is still alive, a timer mechanism will have to be used or a ping system.
Additionally mechanisms to deal with recovery and clean up are also required.
( Retrieving the SNS ARN, removing old endpoints from topic, resubscribing)
The first restriction is a more severe one, with only 25 topics to be created our suggestion of providing one for every job is unattainable.
Therefor we will just create 1 topic but provide specific message structures and titles.
This will cause overhead because every message is send to every endpoint.
If there are enough topics left it is suggested to create one for every master.
If there are enough topics left it is suggested to create one for every master.
We will need to decide if this is worth the effort.
A second thought that arose while working on making all the changes was the necessity of the input and output queue's.
Their main reason of being there is in order for the workers to retrieve work from those queue's.
This is actually not practical in our cloud setting.
We will need to start up instances, they have to perform work and afterwards they get shut down.
It would be costly to have those instances wait for new work to arrive.
(With the exception of the hour rule, where you pay for every hour in which your instance is running.)
Therefor just sending the job through userdata when starting up the instance or providing it through SNS seems more efficient.
The same reasoning can be made for the output queue.
To take the best of both worlds a new SQS queue can be created which will be used to perform the ping-like tactics which were discussed earlier in SNS.
Doing this in SNS would mean every X seconds sending a ping message from every worker to the topic which will in turn reach every worker and the master.
This would mean a lot of overhead and is actually the perfect job for an SQS queue.
Mainly because the order of arrival does not matter nor is there a very strict deadline of delivery.
To summarize the changes to the proposal:
A second thought that arose while working on making all the changes was the necessity of the input and output queue's.
Their main reason of being there is in order for the workers to retrieve work from those queue's.
This is actually not practical in our cloud setting.
We will need to start up instances, they have to perform work and afterwards they get shut down.
It would be costly to have those instances wait for new work to arrive.
(With the exception of the hour rule, where you pay for every hour in which your instance is running.)
Therefor just sending the job through userdata when starting up the instance or providing it through SNS seems more efficient.
The same reasoning can be made for the output queue.
To take the best of both worlds a new SQS queue can be created which will be used to perform the ping-like tactics which were discussed earlier in SNS.
Doing this in SNS would mean every X seconds sending a ping message from every worker to the topic which will in turn reach every worker and the master.
This would mean a lot of overhead and is actually the perfect job for an SQS queue.
Mainly because the order of arrival does not matter nor is there a very strict deadline of delivery.
To summarize the changes to the proposal:
- Only use 1 SNS topic (for every master)
- Remove the input / output SQS queue, replace by userdata and SNS
- Create a PING SQS queue to inform the master of workers being alive.